MotivationOur goal was to predict overall listing ratings on Airbnb spaces in Chicago based on the attributes of each listing. Airbnb has grown by 153% since 2009, increasing its total worldwide value to $32 billion. However, only 11% of the nearly 500,000 US listings are reserved on a typical night (https://ipropertymanagement.com/airbnb-statistics/). The goal of our project is to predict Airbnb property attributes that entice guests on Airbnb, based on the wording that the host uses in their descriptions of the room. This could help hosts cater to the wants of guests in order to maximize guests’ and hosts’ utility from the use of the site. This will also help hosts in preparing and marketing their listings to maximize ratings and thus usage.
Airbnb is 6% to 17% cheaper than hotels in the largest 25 cities in the United States. This coupled with declining hotel nightly rate growth will lead to Airbnb taking over hotels’ revenues in 20 years. As more users begin to use the site, hosts need a way to understand how best to market themselves to guests and use the site to its full potential. We think our project is particularly interesting because there exists current research into how to predict price of an Airbnb, but we also believe the conclusions drawn from our model will be helpful to hosts in understanding how to maximize the value and attractiveness of their listing. We divided the text of each listing into three categories: convenience, budget, and luxury. Using a variant of a bag-of-words algorithm and counter from NLTK and Collections, respectively, we will be counting the number of words that fall into each category and trying to predict the rating of the listing based on the count of words. |

|
Data Exploration
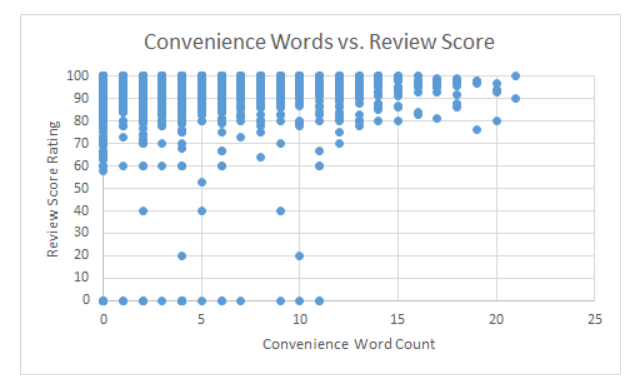
Convenience vs. Review Score |
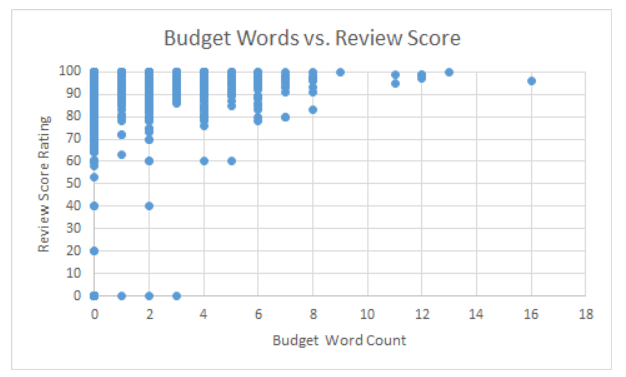
Budget vs. Review Score |
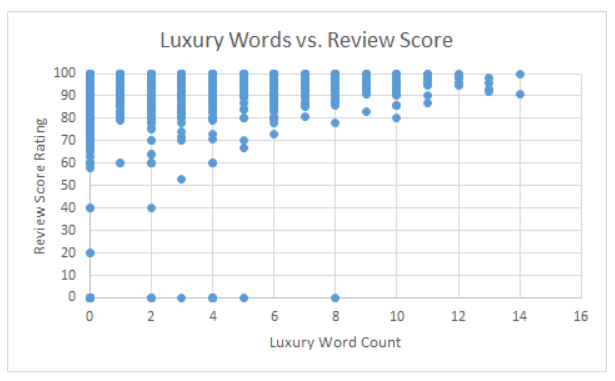
Luxury vs. Review Score |
In order to accomplish our task and count the different types of words found in each listing, we downloaded the Airbnb listings data for Chicago that is provided freely on the Internet (http://insideairbnb.com/get-the-data.html). After our initial data exploration, we found that there may be a slight trend in word count vs. review scores for the Airbnb listings, especially for budget and luxury-type words. The data show that listing that have higher word counts for budget and luxury-related words tend to have higher ratings, while listings with lower word counts are much more varied in their ratings. This result may provide evidence that users are more often drawn to listings that emphasize money-related features of the room rather than how conveniently located the room is in the city. However, the weakness of the correlation makes it difficult to determine whether these words specifically have an impact on whether a user is more likely to rate a room highly or not.
We also wanted to explore potential correlations between variables such as price and review score, number of reviews and review score, word count and price, etc. We chose these variables to explore because they might be potential confounding variables in our experiment that may lead us to draw erroneous conclusions about the effects of word counts on review score. The graphs and results generated from these explorations can be viewed in full in our more detailed final report.
We also wanted to explore potential correlations between variables such as price and review score, number of reviews and review score, word count and price, etc. We chose these variables to explore because they might be potential confounding variables in our experiment that may lead us to draw erroneous conclusions about the effects of word counts on review score. The graphs and results generated from these explorations can be viewed in full in our more detailed final report.
Data Pre-processing
|
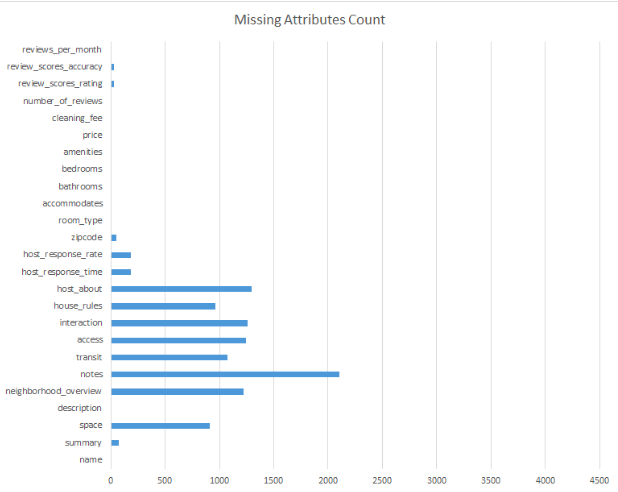
Since we had a large amount of textual data in the listing descriptions, we created our own bag-of-words type of algorithm in Python to look at all of the words in our listings document and count the number of words for each category (convenience, luxury, and budget -- lists of words corresponding to each category that we created). We also had missing values for certain attributes and handled it by domain knowledge and filling with 0's or mean values, depending on the case.
After writing the algorithm to count the number of words, we used Python to implement K-nearest neighbors and linear regression techniques to predict the ratings of the test listings, which we discuss in the next section. |
|
